Linear Algebra Applications
IntroductionMatrices as Images
Linear Regression
Euclidean Distance
Connecting Flights
Descriptors in Dracula
Higher Dimensions and Linear Regression
Prerequisites
- The basic concept of vectors
- The motivation of linear regression, on the level of this explanation
Introduction
If, at this Thanksgiving, I were to ask a relative what the fourth dimension was, they would probably say time. If I were then to ask them what the fifth dimension was, they would either say they didn’t know or give me a sour face and walk away. Most of us do tend to think of the word “dimension” as representing a spatial or temporal quantity, i.e., something that fits within our physical experience.
Suppose, instead, that I were to ask a well-chosen relative why the Chargers were going to win the Super Bowl this year. A lengthy discussion would ensue over the quality of the quarterback, the experience of the coaching staff, the number of injuries they experienced, their current win-streak, and a host of other items. Similarly, if I were to ask a different person why they thought Alphabet’s share prices were going to increase, they would discuss the current management, the new product’s they have in development, the favorable review by some market analyst, their historical growth trends, and so on. Finally, if I were to ask someone else why cousin Casey was still single, they would discuss how they are shy, they spend too much time in Youtube’s comment section, or they never accept the blind-dates everyone in the family sets up for them.
In all of these cases, we reasonably assume that the answers are multi-faceted or, more appropriately here, multi-dimensional. In fact, while some components may be more influential than the others, we expect each of these individual dimensions to contribute something to the final answer.
In this article, we will try to decouple the word “dimension” from the physical and instead develop a framework where “dimension” means something closer to component or attribute of the whole, each independent of the others and important in its own right. In doing so, we will develop a viewpoint of vectors as a way to organize these components and how numerical values in particular instances of these vectors can give us good information if we have the right interpretations in place. In addition, we will use some basic linear regression ideas in an attempt to deepen our intuition about the broader interplay of all of these components.
Specifically, we will look at the price of wine as it relates to a number of factors. This work was originally done by Orley C. Ashenfelter, and we will work with data as presented by the course The Analytics Edge, available on edX. This short video provides some context for why Ashenfelter performed his research.
2-Dimensional Vectors
Let’s begin by comparing the price of wine and the average growing temperature in the season the grapes were grown (AGST). This means for some bottle of wine, we have two pieces of information, and it is very natural to represent these as an ordered pair: \([Price, AGST] \\\) By doing so, we can systematically list instances of this relationship. For example, our dataset has some of the following observations:
- $[7.5, 17.1]$
- $[8.5, 17.3]$
- $[6.3, 16.3]$
where we have rounded the values and haven’t specified the units of measurement. Each of these can serve as our representation of the corresponding 2-dimensional vector, and each has the general form $[x_1, x_2]$. Note that the order in which we display our information is certainly crucial here, as the first position is reserved exclusively for the Price and the second for AGST.
Furthermore, we can observe that each entry shows us how far away from the origin the vector is in that particular dimension. If we wanted to, we could order these in, say, increasing Price:
- $[6.3, 16.3]$
- $[7.5, 17.1]$
- $[8.5, 17.3]$
and doing so would be entirely independent of what is occurring in the AGST dimension. This would show us, along the Price dimension, the order in which these would appear.
Next, we would like to attempt to visualize these vectors. Each of these 2-dimensional vectors hopefully feels reminiscient of the usual ordered pairs $(x,y)$ that you would see in an algebra course. Indeed, by letting the horizontal axis represent AGST and the vertical axis represent Price, we can associate to each vector a point in the plane:
wine.plot.scatter(x='AGST', y='Price')
plt.xlabel('Average Temperature')
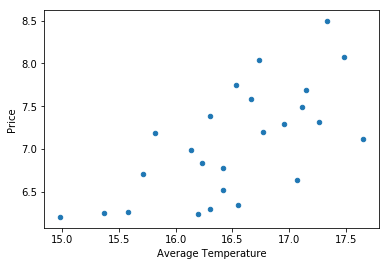
And, every dot on our graph represents a vector given by observations in our data set. For example, we can see one of our earlier examples, $[8.5, 17.3]$, in the top right corner. This provides us with a nice visual way to process the information in our data set. For example, the range in each dimension of our observed values is easy to read at a glance.
From a linear algebraic perspective, price and AGST are both independent variables, and each instance of a vector is represented by the separate information given in the ordered pair. But, this graph certainly seems to suggest that higher priced wines coincide with higher average temperatures. Using our understanding of the way the world works, we can then suggest that there is a causal relationship at play. That is, rather than high price and high temperature simply coinciding with each other, it is more likely that higher temperatures somehow make for a better grape, which in turn makes for better wine, and more may be charged for this better wine. If this is the case, then we should be able to formulate a function for the price of wine based on the average temperature, and linear regression precisely aims to do this using a linear function.
To do so, we will recall that a linear function is of the form \(f(x) = mx + b \\\) where m is the slope of the line and b is the vertical intercept. Because we are now assuming a functional relationship in our data, let’s rewrite our dependent variable, Price, as $y$ and our independent variable, AGST, as $x_1$. Also, to match the typical literature on this topic, we will let $\beta_0$ be our vertical intercept and $\beta_1$ be our coefficient on $x_1$. With these changes our linear model is given by \(y=\beta_0 + \beta_1 x_1 \\\) where such a model is referred to as a simple linear regression model, because there is only one independent variable.
Our task now becomes to decide which line would best describe the relationship between our dependent and independent variables. Certainly, there are many choices for such a line:
fig = plt.figure(figsize=(18, 5))
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
ax1.scatter(wine.AGST,wine.Price)
ax2.scatter(wine.AGST,wine.Price)
ax3.scatter(wine.AGST,wine.Price)
x = np.linspace(15.,17.9)
ax1.plot(x, .1*x+6.8, linewidth=2.0, color="red")
ax2.plot(x, .63509*x-3.41776, linewidth=2.0, color="red")
ax3.plot(x, -.1*x+7.8, linewidth=2.0, color="red")
plt.show()
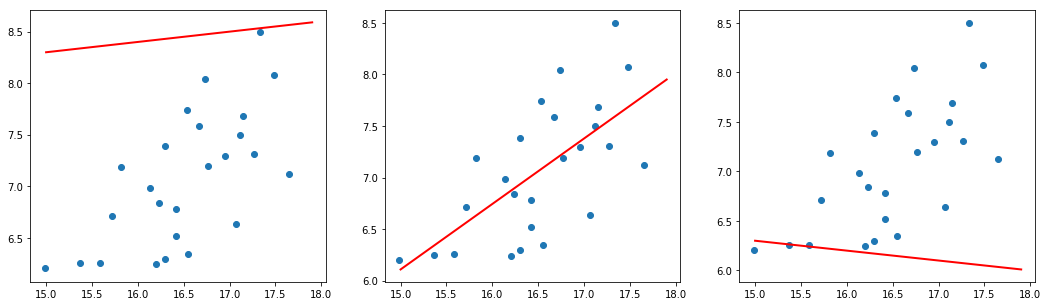
If you have seen linear regression before, then the middle option should immediately jump out as a better fit than the other two. It turns out there is some indication that we are reasonably good at eye-balling the best fit line, but we aren’t perfect at it (see this paper, if you are curious). We make this process rigourous by having a robust method of choosing our coefficients, generally using the ordinary least squares method, but I will save the details for your exploration. In terms of our model, $y=\beta_0 + \beta_1 x_1$, it is noteworthy that, numerically, this indicates that $\beta_1 > 0$.
This certainly seems to give credence to the notion that higher average temperatures lead to better quality wine. But, this also should feel suspiciously simple; surely, other factors must play a role in how wine is priced. In the next section, we will introduce a new variable and redo this work.
Side note: Above I chose to represent our vectors as points in the plane. This may have seemed slightly strange as it is common, especially in class, to represent vectors as an arrow that starts at the origin and ends at the appropriate vector values. This is a perfectly fine way to visualize this information, and in some circumstances is certainly preferrable. But, because our data set contains 25 observations, this gets very visually cluttered:
wine.plot.scatter(x='AGST', y='Price')
for index, row in wine.iterrows():
x=row["AGST"]
y=row["Price"]
plt.plot([0,x],[0,y], color="green")
plt.xlabel('Average Temperature')

Even if we adjust the scale, and mentally track that these vectors start at the origin, the result isn’t much better:
wine.plot.scatter(x='AGST', y='Price')
for index, row in wine.iterrows():
x=row["AGST"]
y=row["Price"]
plt.plot([0,x],[0,y], color="green")
plt.xlim(xmin=14.5, xmax=18)
plt.ylim(ymin=6)
plt.xlabel('Average Temperature')
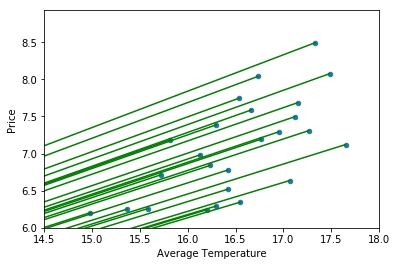
While I do not want to tumble down the rabbit-hole of elements in a vector space here, I do want to observe that a vector is a purely algebraic object. A vector is not the ordered tuple $[x_1, x_2]$, nor is it an arrow with direction and magnitude, nor is it a point in space. All of these are ways in which we represent the underlying vector. As such, we are very much choosing a geometric representation here, and a point in the plane is more suited to our present purposes than an arrow. Furthermore, we will see very shortly that we are unable to rely on our visualizations in general, and debating which visual representation is most accurate is very much beside the point. End of side note.
3-Dimensional Vectors
Let’s introduce a new aspect into our work, the amount of rain during the winter (WinterRain). From a linear algebraic perspective we may represent our data observations as triplets: \([Price, AGST, WinterRain] \\\) For example, our dataset has some of the following observations:
- $[7.5, 17.1, 600]$
- $[8.5, 17.3, 830]$
- $[6.3, 16.3, 574]$
where each of these can serve as our representation of the corresponding 3-dimensional vector, and each has the general form $[x_1, x_2, x_3]$. As before, for some particular observation, the order of the numbers is crucial in our presentation. But, it is noteworthy that the order for the original triplet is entirely arbitrary. That is, the following are all equally valid: \([Price, AGST, WinterRain] \\ \\ [AGST, Price, WinterRain] \\ \\ [WinterRain,Price,AGST] \\\) We are choosing one of these to work with, and while the initial choice is indeed arbitrary (or at least, as valid as any other), we do need to be consistent once we make this choice.
Now that we have established this, we can attempt to visualize the placement of our vectors inside 3-dim space:
from mpl_toolkits.mplot3d import Axes3D
three_dim = plt.figure().gca(projection='3d')
three_dim.scatter(wine['AGST'], wine['WinterRain'], wine['Price'])
three_dim.set_xlabel('Average Temperature')
three_dim.set_ylabel('WinterRain')
three_dim.set_zlabel('Price')
plt.xlim(xmin=13)
plt.ylim(ymin=500)
plt.show()
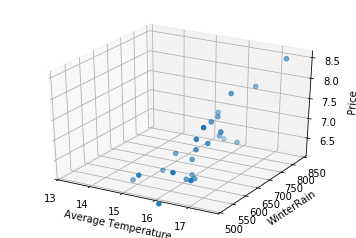
Where the value in each vector representation, e.g., $[7.5, 17.1, 600]$, indicates how far we should move along each axis away from the origin.
As before, if we want to assume a causal relationship, we can designate Price as our dependent variable and AGST and WinterRain as our independent variables. If we label these as $y$, $x_1$, and $x_2$, respectively, then we can express our model as \(y=\beta_0 + \beta_1 x_1 + \beta_2 x_2 \\\) where such a model is referred to as a multiple linear regression model, because there are more than one independent variable.
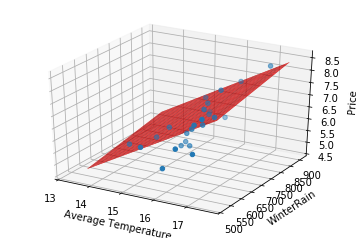
In this case, the best fitting surface will be given by a plane (i.e., a 2-dim space) because it is based on two variables:
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
# scatter
ax.scatter(wine['AGST'], wine['WinterRain'], wine['Price'])
# surface
x = np.linspace(13.5,17.5)
y = np.linspace(550,900)
X,Y = np.meshgrid(x,y)
Z = (-6.55676 + .755205*X + .001910*Y)
ax.plot_surface(X, Y, Z, color="red")
ax.set_xlabel('Average Temperature')
ax.set_ylabel('WinterRain')
ax.set_zlabel('Price')
plt.xlim(xmin=13)
plt.ylim(ymin=500)
plt.show()
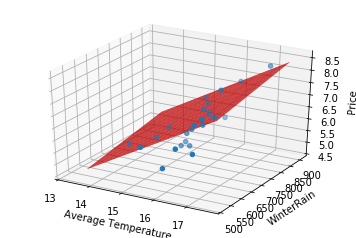
Before we were able to look at the slope of the line, and because it was positively-sloped we concluded that as AGST increased the price would increase as well. Here, we can see a similar relationship in each independent variable. The plane is tilted up as AGST increases and it is tilted up as WinterRain increases. The type of conclusions we draw as we look at each axis individually should feel like repeating the same type of analysis that we did with the line. This visually indicates that each of these variables is contributing to higher prices. In terms of our model, $y=\beta_0 + \beta_1 x_1 + \beta_2 x_2$, this can be expressed numerically as $\beta_1 > 0$ and $\beta_2 >0$.
Hopefully this still feels suspiciously simple; there must be other factors at play. At the same time, the analysis we did here in the 3-dimensional case so strongly mimicked that of the 2-dimensional case that it should feel slightly tedious to keep adding variables one at a time. In the next section, we will add a few more variables into our model in one go.
Higher Dimensional Vectors
In this section, we will extend our problem so that it includes the following components:
- Price: the price of the wine at purhase
- AGST: the average growing season temperature
- WinterRain: the amount of rain during the winter
- HarvestRain: the amount of rain during the harvest season
- Year: the year the wine was produced
- Age: the age of the wine as of 1983
The primary objective for this article was to develop a recognition of each of these components as a dimension in some space. In this case, we would need a 6-dimensional space if we wanted to plot each observation, which is certainly not possible. In fact, even if we wanted to simply add one new component, say HarvestRain, to the work we did above, we would find that we hit our visual limits frustratingly early. Fortunately, while we are no longer able plot our observations, our work in two and three dimensions showed us that we should expect the same type of behaviour in each dimension. This is precisely why vectors have such great utility; they allow us to perform operations that are defined equivalently in two, three, or six dimensions, even if we are not able to actually visualize such work.
From a linear algebraic perspective we may represent our data observations as ordered lists of six items: \([Price, AGST, WinterRain, HarvestRain, Year, Age] \\\) For example, our dataset has some of the following observations:
- $[7.5, 17.1, 600, 160, 1952, 31]$
- $[8.5, 17.3, 830, 38, 1961, 22]$
- $[6.3, 16.3, 574, 184, 1974, 9]$
where each of these can serve as our representation of the corresponding 6-dimensional vector, and each has the general form $[x_1, x_2, x_3, x_4, x_5, x_6]$. As before, each of these numbers tells you how far to move along a particular axis away from the origin, even if you can’t really see that axis in this case.
Sanity check: what would change if I removed Year? what would change if I added the name of the winery? Answer: Not much really; we would have a 5-dim space and 7-dim space, respectively.
As before, we can establish a linear regression on this space, if we assume that Price is dependent on the other variables. With the 3-dim case in mind, I would be willing to wager that you can guess what our model will look like: \(y=\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4 + \beta_5 x_5\)
Now, we have the temporary problem that we can’t graph this model and visually check the slope of the line in each dimension. But, this was really just a visual way of checking the sign of the coefficient on each variable. For example, if we have that $\beta_3 > 0$, then we can conclude that larger amounts of HarvestRain resulted in a higher price. Alternatively, if we have that $\beta_3 < 0$, then we can conclude that larger amounts of HarvestRain resulted in a lower price. If we look at the actual coefficients:
pd.DataFrame(list(zip(x1.columns, lm.coef_)), columns=["Features","EstimatedCoefficients"])
| Features | EstimatedCoefficients | |
|---|---|---|
| 0 | Year | 2.397335e+10 |
| 1 | WinterRain | 1.076179e-03 |
| 2 | AGST | 6.073178e-01 |
| 3 | HarvestRain | -3.974986e-03 |
| 4 | Age | 2.397335e+10 |
we could perform this inspection for each feature (i.e., dimension) of our model.
Closing Thoughts
At this point, I hope it is clear how you could add another, say, 20 dimensions to this work, and it would proceed in largely that same way as the 2-dim and 3-dim case. Furthermore, while we can ask what 20-dim space looks like, I think it is fundamentally the wrong question, and it is significantly hindered by the limitations of our visual skills. Perhaps, rather than thinking of a 20-dim vector as a point in some space that makes no sense to us, we would be better imagining a row of 20 lightbulbs. The values of each dimension may indicate how brightly the corresponding lightbulb shines, where the origin (i.e., a value of 0) is given by off, a dim bulb would indicate we are close to the origin, and increasing brightness indicates we are moving away from the origin. This analogy may not quite work for you, but it can sometimes be helpful to have some mental schema in which you can initially ground these abstract ideas, and then use the formalism of definitions and theorems to refine your understanding. It might also be sufficient to convince yourself that these ideas are straightforward in 2 and 3 dimensions, and to then simply accept that they also work in arbitrary dimensions. Ultimately, I find that the route to internalizing these concepts is incredibly personal, but stick with it and I’m confident that you will find one.
Finally, because our objectives were intuition for linear algebra concepts, I have glossed over much of the technical detail of linear regression. And, there is a good amount of technical detail; I find the concepts of linear regression rather straightforward, but it does take a decent investment of time to become a proficient practitioner.
To this end, a couple brief examples: while you can theoretically add as many dimensions as you would like, it is not necessarily valuable to do so. For example, the coefficients for Year and Age above are the same. This seems reasonable as they are two ways of classifying the same information. While it may be nice to have both in our dataset to save some mental arithmetic, we certainly don’t need both in our model. Furthermore, we could inadvertently introduce features that numerically appear to have a great deal of effect, but might in reality have nothing to do with the price of wine. For example, we could introduce dimensions that tracked France’s ranking in the world cup or the alignment of the stars in the year the wine was produced. Clearly, including these would be nonsensical, but it is often much more subtle, and good tools for testing the significance of a variable are needed. Developing an accurate model takes more care than throwing spaghetti against the wall and finding patterns.
Luckily, there are numerous resources at your disposal to learn linear regression, and I will leave them to your curiosity.
Appendix: Tools Used
While it does not inform the above discussion, I have included here much of the initial work-through for developing the model.
import pandas as pd
wine = pd.read_csv("~/library/higher-dimensions-and-linear-regression/wine.csv", header=0)
wine_test = pd.read_csv("~/library/higher-dimensions-and-linear-regression/wine_test.csv", header=0)
wine = wine.drop(['FrancePop'], axis=1)
wine.columns
Index(['Year', 'Price', 'WinterRain', 'AGST', 'HarvestRain', 'Age'], dtype='object')
wine
| Year | Price | WinterRain | AGST | HarvestRain | Age | |
|---|---|---|---|---|---|---|
| 0 | 1952 | 7.4950 | 600 | 17.1167 | 160 | 31 |
| 1 | 1953 | 8.0393 | 690 | 16.7333 | 80 | 30 |
| 2 | 1955 | 7.6858 | 502 | 17.1500 | 130 | 28 |
| 3 | 1957 | 6.9845 | 420 | 16.1333 | 110 | 26 |
| 4 | 1958 | 6.7772 | 582 | 16.4167 | 187 | 25 |
| 5 | 1959 | 8.0757 | 485 | 17.4833 | 187 | 24 |
| 6 | 1960 | 6.5188 | 763 | 16.4167 | 290 | 23 |
| 7 | 1961 | 8.4937 | 830 | 17.3333 | 38 | 22 |
| 8 | 1962 | 7.3880 | 697 | 16.3000 | 52 | 21 |
| 9 | 1963 | 6.7127 | 608 | 15.7167 | 155 | 20 |
| 10 | 1964 | 7.3094 | 402 | 17.2667 | 96 | 19 |
| 11 | 1965 | 6.2518 | 602 | 15.3667 | 267 | 18 |
| 12 | 1966 | 7.7443 | 819 | 16.5333 | 86 | 17 |
| 13 | 1967 | 6.8398 | 714 | 16.2333 | 118 | 16 |
| 14 | 1968 | 6.2435 | 610 | 16.2000 | 292 | 15 |
| 15 | 1969 | 6.3459 | 575 | 16.5500 | 244 | 14 |
| 16 | 1970 | 7.5883 | 622 | 16.6667 | 89 | 13 |
| 17 | 1971 | 7.1934 | 551 | 16.7667 | 112 | 12 |
| 18 | 1972 | 6.2049 | 536 | 14.9833 | 158 | 11 |
| 19 | 1973 | 6.6367 | 376 | 17.0667 | 123 | 10 |
| 20 | 1974 | 6.2941 | 574 | 16.3000 | 184 | 9 |
| 21 | 1975 | 7.2920 | 572 | 16.9500 | 171 | 8 |
| 22 | 1976 | 7.1211 | 418 | 17.6500 | 247 | 7 |
| 23 | 1977 | 6.2587 | 821 | 15.5833 | 87 | 6 |
| 24 | 1978 | 7.1860 | 763 | 15.8167 | 51 | 5 |
wine.describe()
| Year | Price | WinterRain | AGST | HarvestRain | Age | |
|---|---|---|---|---|---|---|
| count | 25.000000 | 25.000000 | 25.000000 | 25.000000 | 25.000000 | 25.000000 |
| mean | 1965.800000 | 7.067224 | 605.280000 | 16.509336 | 148.560000 | 17.200000 |
| std | 7.691987 | 0.650341 | 132.277965 | 0.675397 | 74.419464 | 7.691987 |
| min | 1952.000000 | 6.204900 | 376.000000 | 14.983300 | 38.000000 | 5.000000 |
| 25% | 1960.000000 | 6.518800 | 536.000000 | 16.200000 | 89.000000 | 11.000000 |
| 50% | 1966.000000 | 7.121100 | 600.000000 | 16.533300 | 130.000000 | 17.000000 |
| 75% | 1972.000000 | 7.495000 | 697.000000 | 17.066700 | 187.000000 | 23.000000 |
| max | 1978.000000 | 8.493700 | 830.000000 | 17.650000 | 292.000000 | 31.000000 |
from sklearn.linear_model import LinearRegression
#exclude our chosen dependent variable from our dataframe
x1 = wine.drop('Price', axis =1)
#establish the linear regression object
lm = LinearRegression()
#fit this model to our data
lm.fit(x1, wine.Price)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
print(lm.intercept_)
-47539160004911.56
#visualize our features and corresponding coefficients
pd.DataFrame(list(zip(x1.columns, lm.coef_)), columns=["Features","EstimatedCoefficients"])
| Features | EstimatedCoefficients | |
|---|---|---|
| 0 | Year | 2.397335e+10 |
| 1 | WinterRain | 1.076179e-03 |
| 2 | AGST | 6.073178e-01 |
| 3 | HarvestRain | -3.974986e-03 |
| 4 | Age | 2.397335e+10 |
And, this is as much as we need for the above discussion. Certainly, from a data analysis perspective, there is a bit more to do to understand this question. Notable next steps would be to run our model against our testing data, remove parameters according to MSE scores, and inspect residuals. I will save this for another project in which it is not buried in an appendix.
Let’s now adjust the above to develop the simple linear regression, on Average Temperature
#drop all variables except AGST
x2 = wine.drop(['Price','Year','WinterRain','HarvestRain','Age','FrancePop'], axis =1)
#establish the linear regression object
lm = LinearRegression()
#fit this model to our data
lm.fit(x2, wine.Price)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
print(lm.intercept_)
-3.4177613134854603
#visualize our features and corresponding coefficients
pd.DataFrame(list(zip(x2.columns, lm.coef_)), columns=["Features","EstimatedCoefficients"])
| Features | EstimatedCoefficients | |
|---|---|---|
| 0 | AGST | 0.635094 |
import matplotlib.pyplot as plt
wine.plot.scatter(x='AGST', y='Price')
plt.xlabel('Average Temperature')
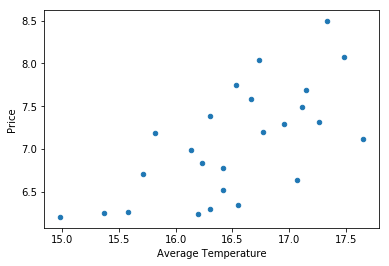
import numpy as np
wine.plot.scatter(x='AGST', y='Price')
x = np.linspace(15.,17.9)
plt.plot(x, .63509*x-3.41776, linewidth=2.0, color="red")
#plt.plot([14.5,18], [5.79105,8.01386], linewidth=2.0)
plt.xlabel('Average Temperature')
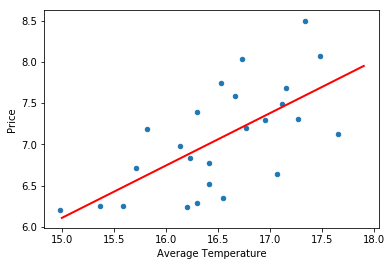
Let’s now extend this model to include two variables, Average Temperature and WinterRain
#drop all variables except AGST and WinterRain
x3 = wine.drop(['Price','Year','HarvestRain','Age','FrancePop'], axis =1)
#establish the linear regression object
lm = LinearRegression()
#fit this model to our data
lm.fit(x3, wine.Price)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
print(lm.intercept_)
-6.556766421260798
#visualize our features and corresponding coefficients
pd.DataFrame(list(zip(x3.columns, lm.coef_)), columns=["Features","EstimatedCoefficients"])
| Features | EstimatedCoefficients | |
|---|---|---|
| 0 | WinterRain | 0.001910 |
| 1 | AGST | 0.755205 |
from mpl_toolkits.mplot3d import Axes3D
three_dim = plt.figure().gca(projection='3d')
three_dim.scatter(wine['AGST'], wine['WinterRain'], wine['Price'])
three_dim.set_xlabel('Average Temperature')
three_dim.set_ylabel('WinterRain')
three_dim.set_zlabel('Price')
plt.xlim(xmin=13)
plt.ylim(ymin=500)
plt.show()
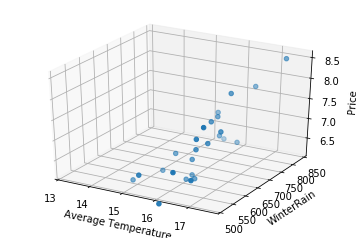
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
# scatter
ax.scatter(wine['AGST'], wine['WinterRain'], wine['Price'])
# surface
x = np.linspace(13.5,17.5)
y = np.linspace(550,900)
X,Y = np.meshgrid(x,y)
Z = (-6.55676 + .755205*X + .001910*Y)
ax.plot_surface(X, Y, Z, color="red")
ax.set_xlabel('Average Temperature')
ax.set_ylabel('WinterRain')
ax.set_zlabel('Price')
plt.xlim(xmin=13)
plt.ylim(ymin=500)
plt.show()