Business Applications
Mobile AppsProduct Reviews
Employee Attrition
Product Reviews: Text Attributes
Contents
- Summary of Results
- Data Source and Discussion
- Length
- Language Diversity
- Descriptor Density
- Most Frequent Descriptors
- Long-Word Density
- Personability
- Storytelling
- Social Network Markers
- Summarize Data
- Future Work
This project is a step towards assessing whether or not a review was considered helpful based on the substance of the text review. To this end, in this project we aim to better understand the structure of our collections of reviews, and do so by augmenting the given dataset with eight variables to reveal text attributes. Specifically, we establish the following:
- Length: A simple measure of the length of each text
- LanguageDiversity: how rich is the language used
- DescriptorDensity: the frequency with which adjectives and adverbs are used to modify or amplify meaning
- MostFrequentDescriptors: a list of the words in the DescriptorDensity that are used with notable frequency
- LongWordDensity: a method of insight into the general accessibility of a text
- Personability: the amount of pronouns and possessives used in order to share personal experience
- Storytelling: the level to which a text provides a narrative structure
- SocialNetworkBinary: a binary measure of the extent to which a text leverages small group consensus
Additional, but brief, discussion for motivation is given in the respective subsections below.
The general structure of these is glimpsed through their respective distributions:
columns_for_hist = ['Length','LanguageDiversity','DescriptorDensity','LongWordDensity','Personability','Storytelling','SocialNetworkBinary']
fig = plt.figure(figsize=[15, 30])
for col in columns_for_hist:
#setup position on canvas
i = columns_for_hist.index(col)
ax = fig.add_subplot(4,2,i+1)
#the actual plot
ax.hist(reviews_sample[col])
ax.set_title(col)
ax.xaxis.set_ticks_position('bottom')
plt.subplots_adjust(hspace = 0.2)
plt.show()
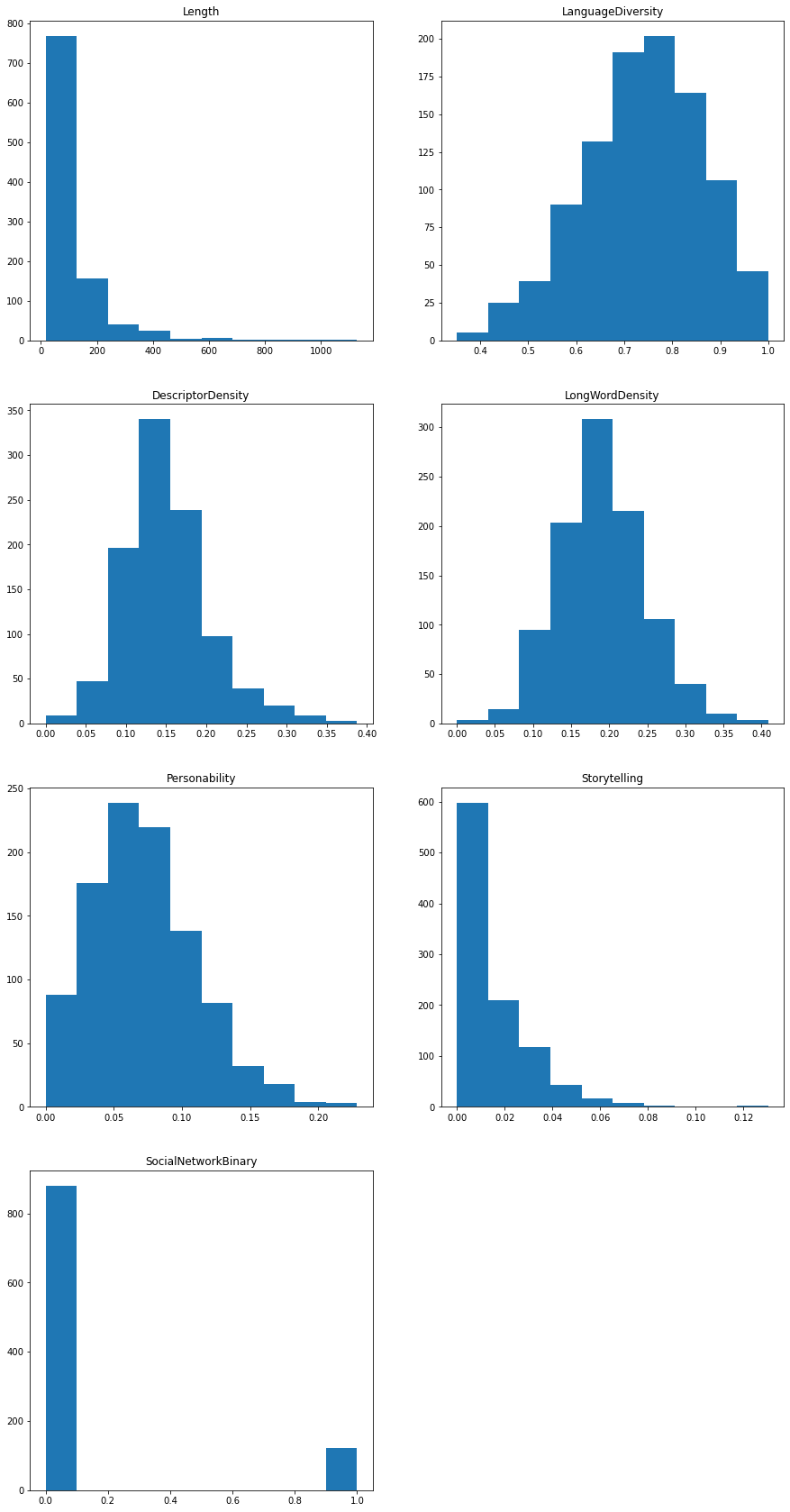
Notably, the above results indicate that, with the possible exceptions of Length, Storytelling, and SocialNetworkBinary, there is enough variation within the dataset that we should proceed with inspecting their impact on the helpfulness score of each review.
Note: we don’t expect any single attribute to have much independent value and future modelling will need to account for their interaction, i.e., we expect substantial instances of collinearity. For example, short reviews like “This was great!” have a much higher probability of realizing greater language diversity scores.
<h2>Data Source and Discussion</h2>
The data are made available by The Stanford Network Analysis Project. Included are 568,454 reviews from 256,059 users spanning 74,258 products. The variables included for each observation are:
reviews.columns
Index(['Id', 'ProductId', 'UserId', 'ProfileName', 'HelpfulnessNumerator',
'HelpfulnessDenominator', 'Score', 'Time', 'Summary', 'Text'],
dtype='object')
Before beginning the actual work, we will arbitrarily choose two reviews to serve as working examples and walk through the reasoning of our desired attributes. While we establish a good number of attributes, most are fairly intuitive and we keep the associated discussions as short as possible. In the course of establishing these attributes, we will write the general functions we will need when we apply our reasoning to the entire dataset.
Note: we will refer to an instance of a review as either “review” or “text”, with no difference in meaning.
#setup our standard environment and a dataframe of the dataset
import pandas as pd
import numpy as np
reviews = pd.read_csv('Reviews.csv')
#we will use the nltk package to perform our NLP
#punkt is the tokenizer
import nltk
nltk.download('punkt')
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Thomas\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
True
#use python builtin to efficiently perform the requisite counting
from collections import Counter
#arbitrarily choose our two worked examples and convert it into the two formats that the package requires
#note: we retain the raw text as its own variable. this will make some methods easier to apply, e.g., inspecting html structure
raw1 = reviews['Text'][75165]
tokens1 = nltk.word_tokenize(raw1)
ex_text1 = nltk.Text(tokens1)
raw2 = reviews['Text'][275845]
tokens2 = nltk.word_tokenize(raw2)
ex_text2 = nltk.Text(tokens2)
Note: it is possible to remove all punctuation marks before applying the previous step. There are arguments for keeping them and removing them, but we have chosen to leave the reviews as unchanged as possible. We should be aware that, particularly with such short text instances, some of our measurements will be affected by this choice. In particular heavy punctuation users will yield longer lengths and, hence, reduced density measurements. Similarly for those users who include links or other html elements. Removing them would negatively effect the tokenization process. For instance, because we assume that the language contained in the reviews is more casual, we expect a high incidence of contractions, which would split into two tokens in the above process. More thought and experimentation will be required on this topic in future work to find the optimal setup.
For reference, our working examples are:
raw1
"This was an Excellent value of buying on Amazon versus the pet stores.<br />It was packaged and labeled well for shipment.<br /><br />However - the manufacturer's plastic top of the box itself is a little cheap and less functional than I expected. Frankly, the whole top has to come off each time I want to give my dog a single chew.<br /><br />So - I'm actually putting these chews into a Dog treat jar that has a open-and-close top with a tab.<br /><br />The manufacturer could simply change the bulk packaging to a bag. Frankly, a Ziploc bag would be just as functional (and probably have a lower manufacturing cost) than the box."
raw2
'Product was fresh, and well wrapped. All done with obvious care.'
We start with the simplest metric, the length of the review. For now, there is no need to write a general function for this.
len(ex_text1)
147
len(ex_text2)
14
Note: this is a measurement of the number of tokens, not a strict word count.
Normalizing by the length of the text, we will establish a simple measure of how diverse or rich the language used is. Specifically, we will take the quotient of the number of unique words by the length of the text.
def langDiversity(text):
return len(set(text))/len(text)
langDiversity(ex_text1)
0.6122448979591837
langDiversity(ex_text2)
0.9285714285714286
We look at the use of all adjectives and adverbs, and quotient by the length of the text to establish a density score.
#parts-of-speech flagging requires the following to function
nltk.download('averaged_perceptron_tagger')
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\Thomas\AppData\Roaming\nltk_data...
[nltk_data] Package averaged_perceptron_tagger is already up-to-
[nltk_data] date!
True
def descrDens(text):
#returns an arry of 2-tuples (word,POS)
pos_tags = nltk.pos_tag(text)
#flags corresponding to adjectives (JJ) and adverbs (RB), where the R and S "suffixes" indicate comparative and superlative versions, respectively
pos = ["JJ", "JJR", "JJS", "RB", "RBR", "RBS" ]
#we won't use the acutal words here, so just establish a count to increment
count = 0
#perform the actual counting
for x in pos_tags:
if x[1] in pos:
count += 1
return count/len(text)
descrDens(ex_text1)
0.11564625850340136
descrDens(ex_text2)
0.21428571428571427
<h2>Most Frequent Descriptors</h2>
To complement the previous metric, we will collect the 5 most frequently used adjectives and adverbs in each review. But, to improve our tracking of trends within the text, we will only include descriptors that occur more than once.
#this returns the desired results, but need to return and consider the efficiency
def freqDescr(text):
#returns an arry of 2-tuples (word,POS)
pos_tags = nltk.pos_tag(text)
#flags corresponding to adjectives (JJ) and adverbs (RB), where the R and S "suffixes" indicate comparative and superlative versions, respectively
pos = ["JJ", "JJR", "JJS", "RB", "RBR", "RBS" ]
#implement the collecting
descr = [x[0] for x in pos_tags if x[1] in pos]
#remove words that occur once
for key,value in Counter(descr).items():
if value == 1:
descr.remove(key)
#limit our results to the top 5, will return an array of 2-tuples (word, count)
return Counter(descr).most_common(5)
freqDescr(ex_text1)
[('functional', 2)]
freqDescr(ex_text2)
[]
We take 5 as the average length of a word in English (based on some searching, there seems to be a number of different results but they are all clustered around five). And, we define a word as long if it is longer than this average. We divide by the length of the text to establish the density score
def longWord(token):
long = [word for word in token if len(word)>5]
return len(long)/len(token)
longWord(tokens1)
0.19727891156462585
longWord(tokens2)
0.21428571428571427
As a measure of the personability or relatibility of the review, we will measure the pronoun and possessive usage, as a density. This is based on the assumption that other users respond favorably to being able to project themselves into the experiences of others, and this process is made slightly easier through the use of personal pronouns.
#the mechanics here are very much like the descriptor density function
def pronDens(text):
#returns an arry of 2-tuples (word,POS)
pos_tags = nltk.pos_tag(text)
#flags corresponding to personal pronouns (PRP) and possessive version (PRP$)
pos = ["PRP", "PRP$" ]
#we won't use the acutal words here, so just establish a count to increment
count = 0
#perform the actual counting
for x in pos_tags:
#we don't want to include instances of "it"; while they are personal pronouns they are not personable enough for this application
if 'it' not in x[0].lower():
if x[1] in pos:
count += 1
return count/len(text)
pronDens(ex_text1)
0.027210884353741496
pronDens(ex_text2)
0.0
As another perspective on the reasoning underlying the previous metric, we assume that users are able to better identify with those reviews that have a stronger narrative structure. In order to measure the level of storytelling, we will measure the density of the usage of words that denote the passage of time or a sequence of events. The technical implementation here is quite simple (establish key words and check for inclusion), but the ease of this method does create some pitfalls. Notably, such keyword lists are only as useful as they are exhaustive and some included words may have alternate meanings.
#this is functional, but not very elegant and in linear time
def storyDens(tokens):
#adjust our tokens to ignore cases
tokens_uniform = [x.lower() for x in tokens]
#establish our chosen identifies
story_words = ['before','first','next','sometimes','earlier','begin','times','finally','previously','starting','consequently','time','conclusion','formerly','initially','following','occasionally','conclude','previous','originally','turn','periodically','end','past','onset','second','rarely','ultimately','prior','beginning','soon','seldomly','finish','preceding','then','yesterday','outset','henceforth','often','lastly','last','before','third','occasion','until','subsequently','now','advance','start','later','intermittently','after','afterwards','annual','anytime','belated','day','days','delay','delayed','early','evening','everyday','future','hour','late','later','midnight','midmorning','midafternoon','afternoon','minute','moment','momentarily','month','morning','night','nighttime','noon','present','schedule','season','someday','sometime','spring','summer','sunrise','sunset','today','tomorrow','tonight','week','winter','fall','autumn','year']
#establish a count to increment
count = 0
#perform the actual counting
for x in tokens_uniform:
if x in story_words:
count += 1
return count/len(tokens)
storyDens(ex_text1)
0.006802721088435374
storyDens(ex_text2)
0.0
<h2>Social Network Markers</h2>
As yet another angle of attack on the relatability of a review, we will measure the use of words that connote familial or social connection, e.g., son, husband, kid, friend. Because these words are less likely to appear multiple times and because of their assumed high collinearity with the pronoun density, we will establish this metric as a binary.
#the initial setup is similar to storyDens. then exit conditions are simple
def socialBinary(tokens):
#adjust our tokens to ignore cases
tokens_uniform = [x.lower() for x in tokens]
#establish our chosen identifies
social_words = ['father','mother','dad','mom','son','daughter','brother','sister','husband','wife','parent','child','sibling','grandfather','grandmother','grandpa','grandma','grandson','granddaughter','grandparent','grandchild','grandchildren','uncle','aunt','cousin','nephew','niece','stepfather','stepdad','stepmother','stepmom','stepson','stepdaughter','stepsister','stepbrother','kid','kids','grandkids','friend','buddy','pal','acquaintance','classmate','partner','roommate','mate','acquaintance','neighbor','associate','colleague','assistant','boss','supervisor','employee','co-worker','teammate']
#check inclusion, with an exit condition if realized
for x in tokens_uniform:
if x in social_words:
return 1
#this is only realized if the above loop campleted without finding any inclusion
return 0
socialBinary(tokens1)
0
socialBinary(tokens2)
0
<h2>Augmenting our Dataset</h2>
With functions now defined for our metrics, we will apply them to our dataset. Before applying them to the full dataset, we will take a slice as a testing environment and ensure we do not have any errors in doing so.
test_reviews = reviews.iloc[:20,:]
First, if we look at the functions we wrote above, we find that three of them utilize the tokens of the review and five utilize the NLTK text. While it will cost more in storage, we will opt to establish the tokens and NLTK text as their own columns. This has the advantage that we will be able to apply our functions in a vectorized fashion and reduce the computational time.
In order to do this, we will append the two columns to the dataframe, then define functions that will establish the tokens and NLTK text given a row from our dataframe, then use the apply method to populate our columns.
test_reviews = test_reviews.join(pd.DataFrame(
{
'Tokens': np.nan,
'TextNLTK': np.nan
}, index=test_reviews.index
))
def tokenize(row):
raw = row['Text']
tokens = nltk.word_tokenize(raw)
return tokens
def text_to_textNLTK(row):
raw = row['Text']
tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens)
return text
test_reviews['Tokens'] = test_reviews.apply(tokenize, axis=1)
test_reviews['TextNLTK'] = test_reviews.apply(text_to_textNLTK, axis=1)
test_reviews
| Id | ProductId | UserId | ProfileName | HelpfulnessNumerator | HelpfulnessDenominator | Score | Time | Summary | Text | Tokens | TextNLTK | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | B001E4KFG0 | A3SGXH7AUHU8GW | delmartian | 1 | 1 | 5 | 1303862400 | Good Quality Dog Food | I have bought several of the Vitality canned d... | [I, have, bought, several, of, the, Vitality, ... | (I, have, bought, several, of, the, Vitality, ... |
| 1 | 2 | B00813GRG4 | A1D87F6ZCVE5NK | dll pa | 0 | 0 | 1 | 1346976000 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut... | [Product, arrived, labeled, as, Jumbo, Salted,... | (Product, arrived, labeled, as, Jumbo, Salted,... |
| 2 | 3 | B000LQOCH0 | ABXLMWJIXXAIN | Natalia Corres "Natalia Corres" | 1 | 1 | 4 | 1219017600 | "Delight" says it all | This is a confection that has been around a fe... | [This, is, a, confection, that, has, been, aro... | (This, is, a, confection, that, has, been, aro... |
| 3 | 4 | B000UA0QIQ | A395BORC6FGVXV | Karl | 3 | 3 | 2 | 1307923200 | Cough Medicine | If you are looking for the secret ingredient i... | [If, you, are, looking, for, the, secret, ingr... | (If, you, are, looking, for, the, secret, ingr... |
| 4 | 5 | B006K2ZZ7K | A1UQRSCLF8GW1T | Michael D. Bigham "M. Wassir" | 0 | 0 | 5 | 1350777600 | Great taffy | Great taffy at a great price. There was a wid... | [Great, taffy, at, a, great, price, ., There, ... | (Great, taffy, at, a, great, price, ., There, ... |
| 5 | 6 | B006K2ZZ7K | ADT0SRK1MGOEU | Twoapennything | 0 | 0 | 4 | 1342051200 | Nice Taffy | I got a wild hair for taffy and ordered this f... | [I, got, a, wild, hair, for, taffy, and, order... | (I, got, a, wild, hair, for, taffy, and, order... |
| 6 | 7 | B006K2ZZ7K | A1SP2KVKFXXRU1 | David C. Sullivan | 0 | 0 | 5 | 1340150400 | Great! Just as good as the expensive brands! | This saltwater taffy had great flavors and was... | [This, saltwater, taffy, had, great, flavors, ... | (This, saltwater, taffy, had, great, flavors, ... |
| 7 | 8 | B006K2ZZ7K | A3JRGQVEQN31IQ | Pamela G. Williams | 0 | 0 | 5 | 1336003200 | Wonderful, tasty taffy | This taffy is so good. It is very soft and ch... | [This, taffy, is, so, good, ., It, is, very, s... | (This, taffy, is, so, good, ., It, is, very, s... |
| 8 | 9 | B000E7L2R4 | A1MZYO9TZK0BBI | R. James | 1 | 1 | 5 | 1322006400 | Yay Barley | Right now I'm mostly just sprouting this so my... | [Right, now, I, 'm, mostly, just, sprouting, t... | (Right, now, I, 'm, mostly, just, sprouting, t... |
| 9 | 10 | B00171APVA | A21BT40VZCCYT4 | Carol A. Reed | 0 | 0 | 5 | 1351209600 | Healthy Dog Food | This is a very healthy dog food. Good for thei... | [This, is, a, very, healthy, dog, food, ., Goo... | (This, is, a, very, healthy, dog, food, ., Goo... |
| 10 | 11 | B0001PB9FE | A3HDKO7OW0QNK4 | Canadian Fan | 1 | 1 | 5 | 1107820800 | The Best Hot Sauce in the World | I don't know if it's the cactus or the tequila... | [I, do, n't, know, if, it, 's, the, cactus, or... | (I, do, n't, know, if, it, 's, the, cactus, or... |
| 11 | 12 | B0009XLVG0 | A2725IB4YY9JEB | A Poeng "SparkyGoHome" | 4 | 4 | 5 | 1282867200 | My cats LOVE this "diet" food better than thei... | One of my boys needed to lose some weight and ... | [One, of, my, boys, needed, to, lose, some, we... | (One, of, my, boys, needed, to, lose, some, we... |
| 12 | 13 | B0009XLVG0 | A327PCT23YH90 | LT | 1 | 1 | 1 | 1339545600 | My Cats Are Not Fans of the New Food | My cats have been happily eating Felidae Plati... | [My, cats, have, been, happily, eating, Felida... | (My, cats, have, been, happily, eating, Felida... |
| 13 | 14 | B001GVISJM | A18ECVX2RJ7HUE | willie "roadie" | 2 | 2 | 4 | 1288915200 | fresh and greasy! | good flavor! these came securely packed... the... | [good, flavor, !, these, came, securely, packe... | (good, flavor, !, these, came, securely, packe... |
| 14 | 15 | B001GVISJM | A2MUGFV2TDQ47K | Lynrie "Oh HELL no" | 4 | 5 | 5 | 1268352000 | Strawberry Twizzlers - Yummy | The Strawberry Twizzlers are my guilty pleasur... | [The, Strawberry, Twizzlers, are, my, guilty, ... | (The, Strawberry, Twizzlers, are, my, guilty, ... |
| 15 | 16 | B001GVISJM | A1CZX3CP8IKQIJ | Brian A. Lee | 4 | 5 | 5 | 1262044800 | Lots of twizzlers, just what you expect. | My daughter loves twizzlers and this shipment ... | [My, daughter, loves, twizzlers, and, this, sh... | (My, daughter, loves, twizzlers, and, this, sh... |
| 16 | 17 | B001GVISJM | A3KLWF6WQ5BNYO | Erica Neathery | 0 | 0 | 2 | 1348099200 | poor taste | I love eating them and they are good for watch... | [I, love, eating, them, and, they, are, good, ... | (I, love, eating, them, and, they, are, good, ... |
| 17 | 18 | B001GVISJM | AFKW14U97Z6QO | Becca | 0 | 0 | 5 | 1345075200 | Love it! | I am very satisfied with my Twizzler purchase.... | [I, am, very, satisfied, with, my, Twizzler, p... | (I, am, very, satisfied, with, my, Twizzler, p... |
| 18 | 19 | B001GVISJM | A2A9X58G2GTBLP | Wolfee1 | 0 | 0 | 5 | 1324598400 | GREAT SWEET CANDY! | Twizzlers, Strawberry my childhood favorite ca... | [Twizzlers, ,, Strawberry, my, childhood, favo... | (Twizzlers, ,, Strawberry, my, childhood, favo... |
| 19 | 20 | B001GVISJM | A3IV7CL2C13K2U | Greg | 0 | 0 | 5 | 1318032000 | Home delivered twizlers | Candy was delivered very fast and was purchase... | [Candy, was, delivered, very, fast, and, was, ... | (Candy, was, delivered, very, fast, and, was, ... |
To perform the vectorized operations, the apply method feeds a row into the given function. As such, we will proceed as follows: (1) append our attribute columns with NaN values, (2) we will define adjusted versions of our attribute functions so that they may leverage our newly created Tokens and TextNLTK columns within the context of an entire row observation, (3) apply these new functions and populate our newly created columns
test_reviews = test_reviews.join(pd.DataFrame(
{
'Length': np.nan,
'LanguageDiversity': np.nan,
'DescriptorDensity': np.nan,
'MostFrequentDescriptors': np.nan,
'LongWordDensity': np.nan,
'Personability': np.nan,
'Storytelling': np.nan,
'SocialNetworkBinary': np.nan
}, index=test_reviews.index
))
#we didn't define a function for length, but we will do so here given the row considerations
def rowLength(row):
text = row['TextNLTK']
return len(text)
test_reviews['Length'] = test_reviews.apply(rowLength, axis=1)
def rowLangDiversity(row):
text = row['TextNLTK']
return langDiversity(text)
test_reviews['LanguageDiversity'] = test_reviews.apply(rowLangDiversity, axis=1)
def rowDescrDens(row):
text = row['TextNLTK']
return descrDens(text)
test_reviews['DescriptorDensity'] = test_reviews.apply(rowDescrDens, axis=1)
def rowFreqDescr(row):
text = row['TextNLTK']
return freqDescr(text)
test_reviews['MostFrequentDescriptors'] = test_reviews.apply(rowFreqDescr, axis=1)
def rowLongWord(row):
token = row['Tokens']
return longWord(token)
test_reviews['LongWordDensity'] = test_reviews.apply(rowLongWord, axis=1)
def rowPronDens(row):
text = row['TextNLTK']
return pronDens(text)
test_reviews['Personability'] = test_reviews.apply(rowPronDens, axis=1)
def rowStoryDens(row):
tokens = row['Tokens']
return storyDens(tokens)
test_reviews['Storytelling'] = test_reviews.apply(rowStoryDens, axis=1)
def rowSocialBinary(row):
tokens = row['Tokens']
return socialBinary(tokens)
test_reviews['SocialNetworkBinary'] = test_reviews.apply(rowSocialBinary, axis=1)
And our dataframe is now given by:
test_reviews
| Id | ProductId | UserId | ProfileName | HelpfulnessNumerator | HelpfulnessDenominator | Score | Time | Summary | Text | Tokens | TextNLTK | Length | LanguageDiversity | DescriptorDensity | MostFrequentDescriptors | LongWordDensity | Personability | Storytelling | SocialNetworkBinary | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | B001E4KFG0 | A3SGXH7AUHU8GW | delmartian | 1 | 1 | 5 | 1303862400 | Good Quality Dog Food | I have bought several of the Vitality canned d... | [I, have, bought, several, of, the, Vitality, ... | (I, have, bought, several, of, the, Vitality, ... | 51 | 0.803922 | 0.156863 | [(better, 2)] | 0.294118 | 0.078431 | 0.000000 | 0 |
| 1 | 2 | B00813GRG4 | A1D87F6ZCVE5NK | dll pa | 0 | 0 | 1 | 1346976000 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut... | [Product, arrived, labeled, as, Jumbo, Salted,... | (Product, arrived, labeled, as, Jumbo, Salted,... | 37 | 0.837838 | 0.135135 | [] | 0.324324 | 0.000000 | 0.000000 | 0 |
| 2 | 3 | B000LQOCH0 | ABXLMWJIXXAIN | Natalia Corres "Natalia Corres" | 1 | 1 | 4 | 1219017600 | "Delight" says it all | This is a confection that has been around a fe... | [This, is, a, confection, that, has, been, aro... | (This, is, a, confection, that, has, been, aro... | 109 | 0.660550 | 0.146789 | [(tiny, 2)] | 0.211009 | 0.027523 | 0.009174 | 1 |
| 3 | 4 | B000UA0QIQ | A395BORC6FGVXV | Karl | 3 | 3 | 2 | 1307923200 | Cough Medicine | If you are looking for the secret ingredient i... | [If, you, are, looking, for, the, secret, ingr... | (If, you, are, looking, for, the, secret, ingr... | 46 | 0.847826 | 0.108696 | [] | 0.239130 | 0.108696 | 0.000000 | 0 |
| 4 | 5 | B006K2ZZ7K | A1UQRSCLF8GW1T | Michael D. Bigham "M. Wassir" | 0 | 0 | 5 | 1350777600 | Great taffy | Great taffy at a great price. There was a wid... | [Great, taffy, at, a, great, price, ., There, ... | (Great, taffy, at, a, great, price, ., There, ... | 32 | 0.718750 | 0.125000 | [] | 0.062500 | 0.031250 | 0.000000 | 0 |
| 5 | 6 | B006K2ZZ7K | ADT0SRK1MGOEU | Twoapennything | 0 | 0 | 4 | 1342051200 | Nice Taffy | I got a wild hair for taffy and ordered this f... | [I, got, a, wild, hair, for, taffy, and, order... | (I, got, a, wild, hair, for, taffy, and, order... | 88 | 0.738636 | 0.147727 | [(only, 2)] | 0.181818 | 0.079545 | 0.000000 | 1 |
| 6 | 7 | B006K2ZZ7K | A1SP2KVKFXXRU1 | David C. Sullivan | 0 | 0 | 5 | 1340150400 | Great! Just as good as the expensive brands! | This saltwater taffy had great flavors and was... | [This, saltwater, taffy, had, great, flavors, ... | (This, saltwater, taffy, had, great, flavors, ... | 57 | 0.824561 | 0.175439 | [] | 0.263158 | 0.017544 | 0.000000 | 0 |
| 7 | 8 | B006K2ZZ7K | A3JRGQVEQN31IQ | Pamela G. Williams | 0 | 0 | 5 | 1336003200 | Wonderful, tasty taffy | This taffy is so good. It is very soft and ch... | [This, taffy, is, so, good, ., It, is, very, s... | (This, taffy, is, so, good, ., It, is, very, s... | 30 | 0.833333 | 0.233333 | [] | 0.200000 | 0.066667 | 0.000000 | 0 |
| 8 | 9 | B000E7L2R4 | A1MZYO9TZK0BBI | R. James | 1 | 1 | 5 | 1322006400 | Yay Barley | Right now I'm mostly just sprouting this so my... | [Right, now, I, 'm, mostly, just, sprouting, t... | (Right, now, I, 'm, mostly, just, sprouting, t... | 29 | 0.896552 | 0.172414 | [] | 0.172414 | 0.137931 | 0.034483 | 0 |
| 9 | 10 | B00171APVA | A21BT40VZCCYT4 | Carol A. Reed | 0 | 0 | 5 | 1351209600 | Healthy Dog Food | This is a very healthy dog food. Good for thei... | [This, is, a, very, healthy, dog, food, ., Goo... | (This, is, a, very, healthy, dog, food, ., Goo... | 29 | 0.827586 | 0.206897 | [] | 0.206897 | 0.103448 | 0.000000 | 0 |
| 10 | 11 | B0001PB9FE | A3HDKO7OW0QNK4 | Canadian Fan | 1 | 1 | 5 | 1107820800 | The Best Hot Sauce in the World | I don't know if it's the cactus or the tequila... | [I, do, n't, know, if, it, 's, the, cactus, or... | (I, do, n't, know, if, it, 's, the, cactus, or... | 184 | 0.554348 | 0.130435 | [(n't, 3), (hot, 3), (once, 2)] | 0.168478 | 0.081522 | 0.005435 | 0 |
| 11 | 12 | B0009XLVG0 | A2725IB4YY9JEB | A Poeng "SparkyGoHome" | 4 | 4 | 5 | 1282867200 | My cats LOVE this "diet" food better than thei... | One of my boys needed to lose some weight and ... | [One, of, my, boys, needed, to, lose, some, we... | (One, of, my, boys, needed, to, lose, some, we... | 72 | 0.736111 | 0.111111 | [(higher, 2)] | 0.152778 | 0.069444 | 0.013889 | 0 |
| 12 | 13 | B0009XLVG0 | A327PCT23YH90 | LT | 1 | 1 | 1 | 1339545600 | My Cats Are Not Fans of the New Food | My cats have been happily eating Felidae Plati... | [My, cats, have, been, happily, eating, Felida... | (My, cats, have, been, happily, eating, Felida... | 86 | 0.686047 | 0.162791 | [(new, 3), (now, 2)] | 0.151163 | 0.093023 | 0.046512 | 0 |
| 13 | 14 | B001GVISJM | A18ECVX2RJ7HUE | willie "roadie" | 2 | 2 | 4 | 1288915200 | fresh and greasy! | good flavor! these came securely packed... the... | [good, flavor, !, these, came, securely, packe... | (good, flavor, !, these, came, securely, packe... | 19 | 0.842105 | 0.263158 | [] | 0.263158 | 0.052632 | 0.000000 | 0 |
| 14 | 15 | B001GVISJM | A2MUGFV2TDQ47K | Lynrie "Oh HELL no" | 4 | 5 | 5 | 1268352000 | Strawberry Twizzlers - Yummy | The Strawberry Twizzlers are my guilty pleasur... | [The, Strawberry, Twizzlers, are, my, guilty, ... | (The, Strawberry, Twizzlers, are, my, guilty, ... | 24 | 0.916667 | 0.083333 | [] | 0.250000 | 0.125000 | 0.000000 | 1 |
| 15 | 16 | B001GVISJM | A1CZX3CP8IKQIJ | Brian A. Lee | 4 | 5 | 5 | 1262044800 | Lots of twizzlers, just what you expect. | My daughter loves twizzlers and this shipment ... | [My, daughter, loves, twizzlers, and, this, sh... | (My, daughter, loves, twizzlers, and, this, sh... | 29 | 0.862069 | 0.068966 | [] | 0.344828 | 0.068966 | 0.000000 | 1 |
| 16 | 17 | B001GVISJM | A3KLWF6WQ5BNYO | Erica Neathery | 0 | 0 | 2 | 1348099200 | poor taste | I love eating them and they are good for watch... | [I, love, eating, them, and, they, are, good, ... | (I, love, eating, them, and, they, are, good, ... | 45 | 0.777778 | 0.111111 | [] | 0.155556 | 0.200000 | 0.022222 | 0 |
| 17 | 18 | B001GVISJM | AFKW14U97Z6QO | Becca | 0 | 0 | 5 | 1345075200 | Love it! | I am very satisfied with my Twizzler purchase.... | [I, am, very, satisfied, with, my, Twizzler, p... | (I, am, very, satisfied, with, my, Twizzler, p... | 28 | 0.821429 | 0.142857 | [] | 0.285714 | 0.214286 | 0.000000 | 0 |
| 18 | 19 | B001GVISJM | A2A9X58G2GTBLP | Wolfee1 | 0 | 0 | 5 | 1324598400 | GREAT SWEET CANDY! | Twizzlers, Strawberry my childhood favorite ca... | [Twizzlers, ,, Strawberry, my, childhood, favo... | (Twizzlers, ,, Strawberry, my, childhood, favo... | 157 | 0.649682 | 0.063694 | [] | 0.254777 | 0.038217 | 0.006369 | 0 |
| 19 | 20 | B001GVISJM | A3IV7CL2C13K2U | Greg | 0 | 0 | 5 | 1318032000 | Home delivered twizlers | Candy was delivered very fast and was purchase... | [Candy, was, delivered, very, fast, and, was, ... | (Candy, was, delivered, very, fast, and, was, ... | 31 | 0.774194 | 0.129032 | [] | 0.161290 | 0.064516 | 0.000000 | 0 |
With these working as we would like to in our test environment and acknowledging a hardware limitation on my end, we will follow the same steps for a sample drawn form our dataframe, without further discussion. When done, we will export to a csv to allow for quick entry into future analysis.
reviews = reviews.join(pd.DataFrame(
{
'Tokens': np.nan,
'TextNLTK': np.nan
}, index=reviews.index
))
#apply in chunks
reviews.iloc[550000:,10] = reviews.iloc[550000:,9:12].apply(tokenize, axis=1)
#we will save a version of the dataframe with the populated tokens
reviews.to_csv('reviews_with_tokens.csv', index=False)
#establish our sample
#we will use just a routine sample size, and I will need to think further on the ideal sample size
reviews_sample = reviews.sample(n=1000, random_state=1)
#populate the NLTK text objects
#note these need to be populated in an active session, hence we didn't populate them when we saved the tokens
reviews_sample['TextNLTK'] = reviews_sample.apply(text_to_textNLTK, axis=1)
reviews_sample = reviews_sample.join(pd.DataFrame(
{
'Length': np.nan,
'LanguageDiversity': np.nan,
'DescriptorDensity': np.nan,
'MostFrequentDescriptors': np.nan,
'LongWordDensity': np.nan,
'Personability': np.nan,
'Storytelling': np.nan,
'SocialNetworkBinary': np.nan
}, index=reviews_sample.index
))
reviews_sample['Length'] = reviews_sample.apply(rowLength, axis=1)
reviews_sample['LanguageDiversity'] = reviews_sample.apply(rowLangDiversity, axis=1)
#sluggish based on my use of NLTK; need to optimize
reviews_sample['DescriptorDensity'] = reviews_sample.apply(rowDescrDens, axis=1)
#need to optimize
reviews_sample['MostFrequentDescriptors'] = reviews_sample.apply(rowFreqDescr, axis=1)
reviews_sample['LongWordDensity'] = reviews_sample.apply(rowLongWord, axis=1)
#need to optimize
reviews_sample['Personability'] = reviews_sample.apply(rowPronDens, axis=1)
reviews_sample['Storytelling'] = reviews_sample.apply(rowStoryDens, axis=1)
reviews_sample['SocialNetworkBinary'] = reviews_sample.apply(rowSocialBinary, axis=1)
#we will drop our NLTK related columns and the original text before saving our sample dataframe (on memory considerations)
del reviews_sample['Text']
del reviews_sample['Tokens']
del reviews_sample['TextNLTK']
#save final augmented version of dataframe for quicker entry into analysis
reviews_sample.to_csv('reviews_sample_augmented.csv', index=False)
And, our final result is given by:
reviews_sample.head()
| Id | ProductId | UserId | ProfileName | HelpfulnessNumerator | HelpfulnessDenominator | Score | Time | Summary | Length | LanguageDiversity | DescriptorDensity | MostFrequentDescriptors | LongWordDensity | Personability | Storytelling | SocialNetworkBinary | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 288312 | 288313 | B000ENUC3S | AN66F3Q4QNU43 | Donna Speaker | 0 | 0 | 5 | 1340496000 | Cherry Pie Larabar | 39 | 0.717949 | 0.102564 | [(low, 2)] | 0.076923 | 0.076923 | 0.000000 | 0 |
| 431726 | 431727 | B002TMV3CG | A3G007LQX6KGOD | SevereWX | 0 | 0 | 5 | 1287878400 | Melitta Coffee | 112 | 0.687500 | 0.151786 | [] | 0.294643 | 0.071429 | 0.008929 | 0 |
| 110311 | 110312 | B004867T24 | A11LNY2OLQSUSV | M. Castillo | 0 | 0 | 5 | 1331769600 | great treat | 42 | 0.880952 | 0.166667 | [] | 0.119048 | 0.095238 | 0.000000 | 0 |
| 91855 | 91856 | B004U7KPY0 | A1QCYVHWO5934U | PistolaMia "PistolaMia" | 0 | 0 | 5 | 1332806400 | Daily Calming | 25 | 0.800000 | 0.280000 | [] | 0.240000 | 0.000000 | 0.000000 | 0 |
| 338855 | 338856 | B000FD78R0 | A30U2QQN2FFHE9 | J. Amicucci | 2 | 3 | 5 | 1271376000 | Best Canned Artichokes Out There! | 279 | 0.562724 | 0.186380 | [(not, 5), (too, 3), (just, 2), (couple, 2), (... | 0.182796 | 0.096774 | 0.028674 | 0 |
Because this project has focused on expanding the dataset we were given with potentially useful attributes of the text review (rather than performing the full analysis of how these contribute to the helpfulness score, which we will be the focus of future work), we will end with a simple summary of our data through a view of the distributions of our new attributes.
import matplotlib.pyplot as plt
columns_for_hist = ['Length','LanguageDiversity','DescriptorDensity','LongWordDensity','Personability','Storytelling','SocialNetworkBinary']
fig = plt.figure(figsize=[15, 30])
for col in columns_for_hist:
#setup position on canvas
i = columns_for_hist.index(col)
ax = fig.add_subplot(4,2,i+1)
#the actual plot
ax.hist(reviews_sample[col])
ax.set_title(col)
ax.xaxis.set_ticks_position('bottom')
plt.subplots_adjust(hspace = 0.2)
plt.show()
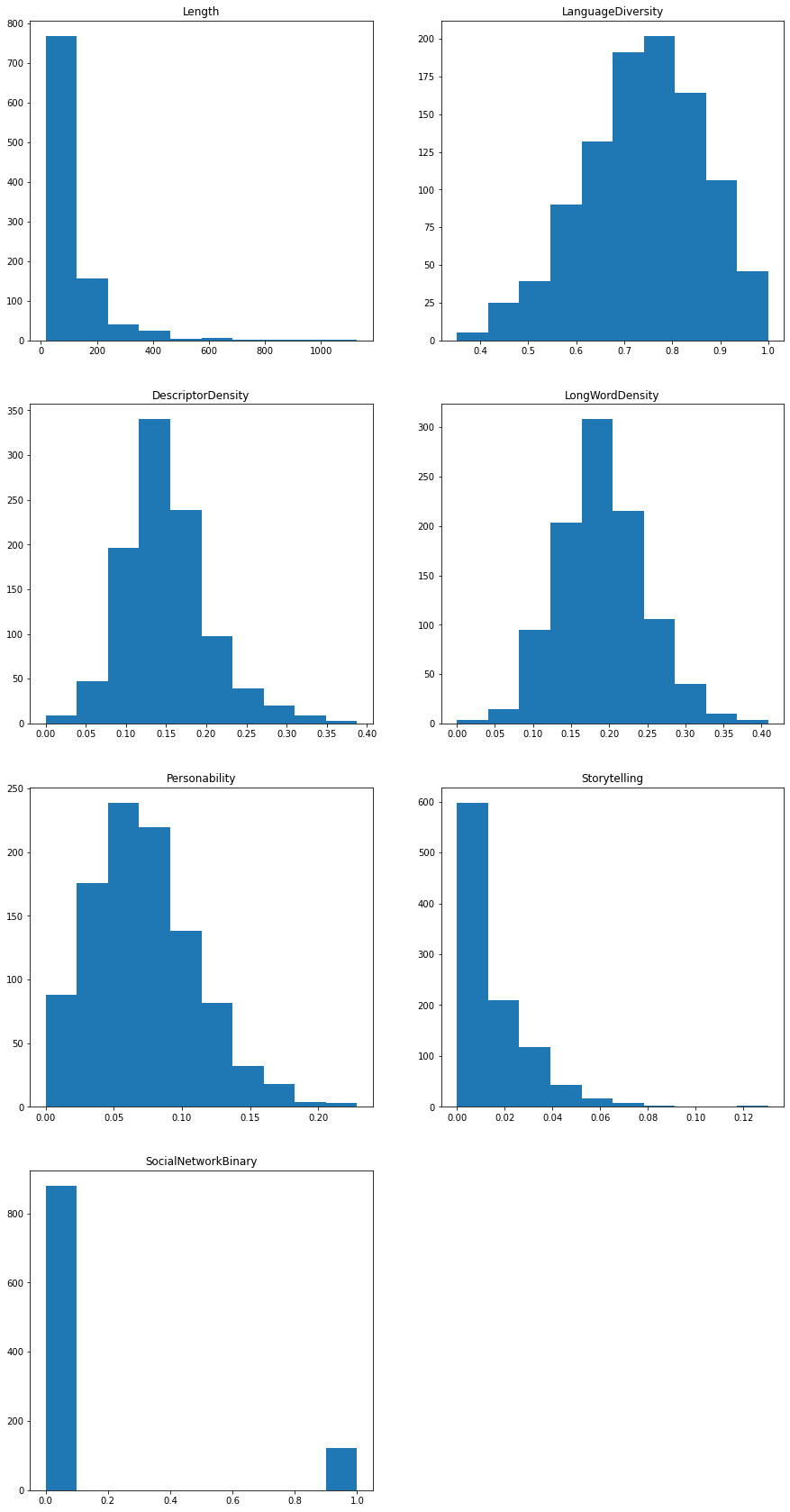
I would also like to establish metrics for spelling error density (NLTK can’t do this, but the Pattern module seems like a good option); how clean the structure of the review is (that is, I assume reviews that are closer to bullet-points are more often marked as helpful than walls of text), probably in the form of some weighted scoring; the occurence of abbreviations and “sms-speech”, e.g., “u”, “gr8”; and if an edit has occured.
I need to spend some more time optimizing this workflow. NLTK doesn’t scale very well in an application of numerous short texts, so I need to think through precisely where it’s needed and the most efficient method to pipe it in.
Most of these attributes were either low-hanging fruit or aspects that I was curious about having any impact, and this project was intended to build some creative muscles. Expanding this work with more established methodologies is certainly necessary, but will take more research.
I have ommitted sentiment analysis. It would be simple enough to apply some density scoring for chosen word groups, but I prefer to delay this feature until I can perform a deeper dive.
The most glaring ommission must certainly be that we have not performed any regression to measure the utility of these attributes. We will do so in a follow-up project.